



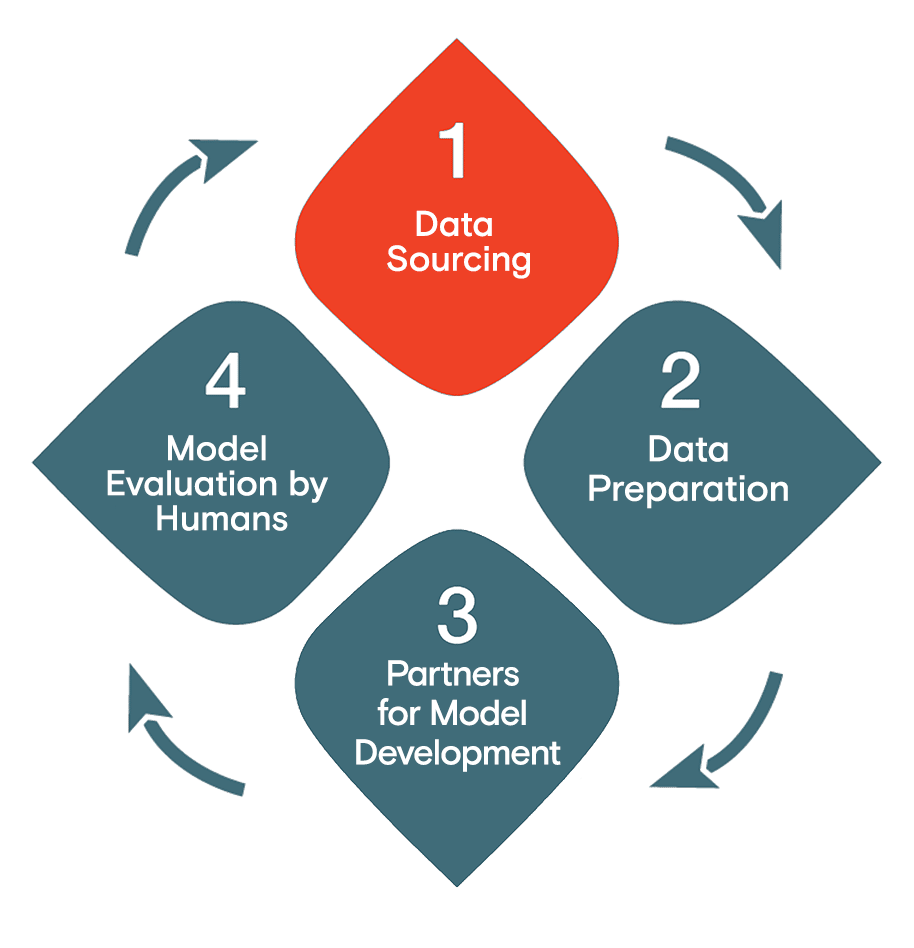
Data for the AI Lifecycle encompasses four main steps in the continuous cycle to deliver high quality data needed for any AI project. The steps are: data sourcing, data preparation, model training and deployment, and model evaluation by humans. Data sourcing, data preparation and model evaluation are the most laborious and data intense and if not done well, can lead to project quality issues and launch delays. AI practitioners spend more than 80% of their time managing data, so they need the best tools and services for this extremely critical part of the process. We specialize in those three stages and strategically partner with providers who specialize in model training and deployment.
Data for the AI Lifecycle
Data Sourcing
Data collection from our global crowd of over 1 million workers gives the ability to provide access to ethically sourced datasets for any use case you may need and is done through our end-to-end managed services. We also offer data sourcing solutions for all organizations, no matter which stage of AI maturity. Pre-labeled datasets will accelerate your AI project by providing your team access to licensable ready-made data specific to your needs. Our catalog of over 250 pre-labeled datasets includes audio, image, text, and video. Lastly, synthetic data is leveraged to generate hard-to-find data to enhance model training.
Data Preparation
Our industry leading platform and machine learning-assisted tools allow our customers to upload their data for our global crowd to provide the annotations, judgements, and labels to create high-quality labeled data for your models. We also offer industry leading knowledge graph and ontology support services to help you build a robust, and powerful knowledge graph, turning your data into intelligence.
Model Training and Deployment
Data for AI Lifecycle is our specialty, and we choose to partner with the experts when it comes to model training and deployment. Whether it’s your in-house team of engineers and data scientists, or you choose to work with our strategic technology partners, we provide your team with the data to train and deploy AI models. Some of our partners include Microsoft Azure, Amazon SageMaker, Google Cloud, NVIDIA, Pachyderm, and PwC Japan.
Model Evaluation by Humans
We offer real-world model performance validation and tuning across a range of use cases and demographics. With industry benchmarks, we can compare model performance to competitors to ensure you are able to receive best-in-class results.
Visit our products and solutions to learn more about our specialization in data sourcing, data preparation, and model evaluation by humans.
Over 25 Years of Expertise
We have been trusted by our customers for over 25 years to provide high-quality training data with an easy-to-use platform that can scale across many use cases and deliver data for AI solutions fast. We work with the top innovative companies including Google, Amazon, Microsoft, Salesforce, Boeing, and Bloomberg.
Trust
Our state-of-the-art data privacy and security provides secure on-site facilities for data annotation and collection capabilities in Europe, US, and the Philippines. We continue to invest in enterprise-grade security features, such as single-sign-on, in our software platforms to enable clients and our work-from-home contributors secure solutions.
Quality
We consistently deliver high-quality results to achieve accuracy threshold commitments. Our In-Platform Quality Management and Smart Validators ensure data annotation errors are minimized and insights are quickly delivered. Our global crowd of over 1 million contributors across over 180 countries provides global representation to provide broad and inclusive datasets.
Usability
Our easy-to-use AI lifecycle management platform provides a powerful API integration layer to connect into your existing MLOps infrastructure. We make management of jobs and models easy with an intuitive user interface and 24/7 support.
Scale
With over 25 years’ experience providing AI solutions, we have a proven record of scaling for the largest dataset sizes delivered by demographics as broad as our clients require.
Speed
Our machine learning-assisted annotation models provide data preparation results at far greater speed than unassisted human annotators. Speed Labeling predicts labels as contributors work to increase efficiencies. Workflows automate multistep data processing steps and sequence sequential jobs with the most effective labelers on each.
Amplify your project success! Connect with our Data for the AI Lifecycle experts, here.
Inclusive and Responsible AI
Speed, scale, and quality should not come at the expense of the annotators working on the data. We believe in responsible data sourcing and annotation and that includes how those workers are treated. Our Crowd Code of Ethics was created in 2018 to show our dedication to the well-being of our crowd and is built on a foundation of fair pay, inclusion, privacy, and confidentiality.
Crowd Code of Ethics
Fair Pay
Our goal is to pay our crowd above minimum wage in every market around the world where we operate.
Inclusion
A diverse, inclusive culture is vital to our mission of helping build better AI. We offer opportunities for individuals of all abilities and backgrounds.
Crowd Voice
Our crowd has a valued voice with us and their feedback helps us to continuously improve.
Privacy and Confidentiality
Any information collected about the crowd is requested solely for the purposes of the project. We take precautions to protect that information and do not release private data on individuals to third parties without consent.
Communication
We believe in helpful, transparent, and responsive lines of communication with our crowd.
Well-Being
We promote wellness, community, and connections through online forums and best practices.
To learn more about our Crowd, visit our Crowd Wellness page.






