




- Autonomous driving
- Automatic image captioning
- Facial recognition and tagging on social media
- Medical imaging analysis and diagnostics
- Home security
- Quality control and defect identification in manufacturing
- and more
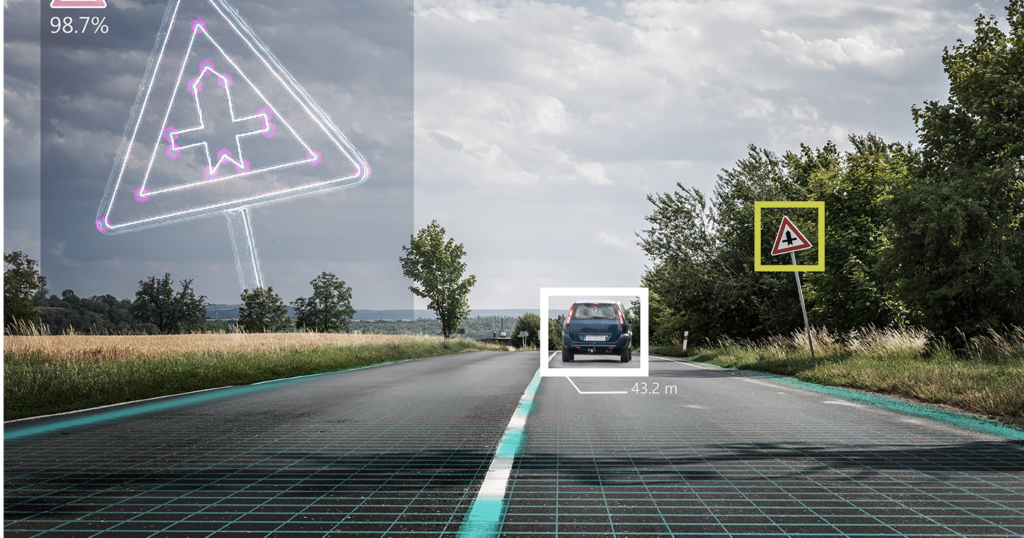
Computer Vision Datasets
To prepare machine learning models and AI algorithms for computer vision projects, you’ll need data. One of the challenges faced by companies working on CV projects is getting enough of the right, high-quality data to be able to train their algorithms. In the last few years, a number of pre-labeled or pre-labeled data sets have been created and released by different companies. You can find open source and for-purchase data sets for every type of use case you can imagine. Common CV tasks include:- Object detection
- Object segmentation
- Multi-object annotation
- Image classification
- Image captioning
- Human pose estimation
- Frame-by-frame video analytics
Pre-labeled Computer Vision Datasets Examples
Training a CV algorithm is a time- and data-intensive project, even more so than training other types of machine learning algorithms. While you might be used to dealing with hundreds or thousands of training data points, that won’t be enough to train a high-quality ML model for CV tasks. Without enough training data, your CV model won’t be able to produce useful results. Because of the challenges of getting enough data to train a CV machine learning model, it’s becoming common to find curated, robust CV data sets available online. When you do find a CV data set online that fits your needs, be sure to evaluate whether or not the data is of high enough quality to be used. Try asking yourself:- Is the source of this data trustworthy?
- Am I able to find and fix any potential inaccuracies in the data?
- Is the data complete and representative?
- Is the data objective? Or does it contain obvious bias?
1. ObjectNet — Best For Unbiased Data
One of the major issues with pre-labeled CV datasets is bias. Many sources of pre-labeled datasets for training CV models use imperfect images scraped from the internet that create bias in the final dataset. ObjectNet was developed by researchers at the MIT-IBM Watson AI Lab. The researchers built the dataset differently than traditional datasets. Instead of curating photos from existing sources, they crowdsourced the images. The team hired a number of different people on Mechanical Turk and requested photos of objects, which were then submitted for review. The image review process evaluated the overall dataset to ensure that there was enough variety in the background, lighting, rotation, and other image factors to limit image bias. The ObjectNet dataset contains 50,000 images that are distributed across 313 object classes. ObjectNet is a different kind of dataset. In some ways, the dataset presents a CV model with clean almost too perfect data. In many images, the objects are centered and the background isn’t cluttered. But, it also has variety, presenting uncommon rotations, perspectives, and viewpoints. While the images wouldn’t confuse a human looking to spot a specific object, they’re great for training a high-quality CV model.2. Appen — Best For International Projects
At Appen, we have over 250 licensable datasets that can work with a variety of different types of CV projects, including audio, speech, video, images, and words. In our pre-labeled datasets, you’ll find both over 25,000 images and 8.7 million words across 80 different languages and dialects Our pre-labeled datasets are designed to make training your CV model efficient and effective. Each dataset is curated to give you the ability to train a highly-accurate CV model at scale. At Appen, we work with a global workforce of over a million contractors, which has allowed us to create one of the best pre-labeled datasets for international projects that are working in more than one language. If you review our pre-labeled datasets and don’t find one that fits your needs, we also offer data collection as a standalone service. We can create a customized dataset for your specific use case.3. VisualData — Best For Recognizing Objects
If your CV model is being built to recognize objects and you need pre-labeled image data, VisualData is a great first place to start looking for the right dataset for your use case. VisualData monitors university labs, social media, and a number of other sources to track new releases of open source datasets. VisualData offers a searchable archive of open source datasets that are available to be used. You can sort that datasets by date published, topic, or search via keyword to locate the right images for your CV use case.4. Graviti — Best For Sharing and Finding Data
Graviti has built an open dataset community where a variety of enterprises, institutions, research groups, and individual developers share, access, and manage large datasets. With over 1000 high-quality, open source datasets that can be used in over 50 application scenarios and more than 10 data formats, Graviti provides data seekers with an ever-expanding variety of datasets to choose from.5. ImageNet — Best For Large Datasets
ImageNet is one of the largest and most popular open source datasets on the market. ImageNet has over 14 million images that have been hand-annotated. The database is organized by WordNet hierarchy and object-level annotations are done with a bounding box.6. Roboflow — Best For Using Different File Formats
Roboflow is all about supporting developers in creating their own computer vision machine learning model, no matter their skillset or team size. Roboflow streamlines the process of building a CV model by helping you get the right data and accurately annotate that data. As part of this streamlining process, Roboflow also has open-source data sets that can be used to train your CV model. The datasets cover a variety of domains, including animals, board games, self-driving cars, medicine, thermal imagery, and aerial drone imagery. Roboflow also offers some pre-labeled data sets made up of synthetic data. Where Roboflow stands out among its competitors is by offering users the ability to download the images in a number of different formats. Those formats include:- VOC XML
- COCO JSON
- YOLOv3 flat text files
- TFRecords
7. GitHub and Kaggle — Best For Finding New or Obscure Datasets
If you’re working on a number of different CV projects and will need multiple datasets, one of the best sources you can use are community-building and sharing platforms such as GitHub and Kaggle. By joining these communities, which are free, you can begin to build your knowledge base of what datasets are out there and which will be the most helpful for your unique projects. With a little patience and the right keywords, you can find some of the newest and most obscure datasets on websites such as GitHub and Kaggle. You can also network with other data scientists and machine learning engineers, who may be able to help you find just the dataset you’re looking for.8. Kinetics — Best For Human-Object Interaction Videos
Kinetics offers an open source dataset that has a total of 650,000 video clips which cover 700 human action classes. The dataset includes human-object interaction and human-human interactions. The dataset can be broken down into sections of 700 video clips. Each video clip in the dataset is annotated and lasts about 10 seconds. The Kinetics dataset is a high quality dataset that can be used for a number of different CV use cases.9. IMDB-WIKI — Best For Gender and Age Identification
If you’re looking to train a CV model that will need to identify a person’s age or gender, you’ll want to use the IMDB-WIKI open source dataset. You can find this dataset on a number of different websites, including GitHub. The IMDB-WIKI dataset includes 523,051 total images. The images have been pulled from Wikipedia and IMDB. Each image is annotated and includes the gender, age, and name of the person in the image. This makes this open source dataset the largest publicly available dataset of human faces available.10. Berkeley DeepDrive — Best For Autonomous Vehicle CV Tasks
One of the most exciting real-world applications of CV technology is with autonomous vehicles. But, before those vehicles can hit the roads, they need hours of training. To make training these CV models more accessible and equitable, UC Berkeley created the Berkeley DeepDrive dataset which has over 100k video sequences. The dataset is open source and is available to the public. The Berkeley DeepDrive dataset includes diverse annotations, including object bounding boxes, drivable areas, image-level tagging, lande markings, and full-frame instance segmentation.How Pre-Labeled CV Datasets Benefit Organizations
The rise of pre-labeled computer vision datasets has allowed organizations to more easily access the data they need to train CV models. There are a wide variety of applications for CV models and many organizations are seeing the ways in which it can be applied to solve problems. As more organizations realize the power of CV models, more organizations will be looking for data to train their CV models. Without pre-labeled datasets, many organizations wouldn’t have the time or resources needed to create a CV model. Pre-labeled datasets allow organizations to devote their resources towards building and training a CV model instead of collecting data. And, the more open source datasets that are available, the higher the quality of data will become. As these datasets improve in quality, so will the CV models that are being used to solve problems throughout organizations.Computer Vision Data Set FAQs
As more and more datasets become available for free online, it’s important to be circumspect with which datasets you use for your project and to understand the benefits of potential datasets over others. These commonly asked questions can help to direct you towards the right dataset for your CV project.Where Can I Get the Right Kind of Data?
When it comes to “the right kind of data,” there are a number of factors to consider. You need your data to be the right:- Type of data (image, video, audio)
- File format
- Number of data points
- Kind of data (unbiased, high-quality, accurately annotated)
How Much Data Do I Need?
While you’ll often hear the guideline that more data is better, there is a cutoff where you have too much data in your dataset. So, how much data is the right amount of data? There isn’t a single number that denotes the right amount of data, but a range can help you to find the right amount of the data for your project. Most CV models need to be trained on several thousand to millions of data points. The more complex your CV model or pattern recognition scenario, the more data points you’ll need in your dataset.How Do I Ensure My Computer Vision Data Set is High Quality?
Throughout this article, we’ve mentioned high quality datasets. But, what makes data high versus low quality? High quality data has to do with how the data has been annotated and the annotation accuracy rate. While some data annotation has been automated, the best, highest quality data annotation is done with a combination of human annotation and automation. When you use high quality data to train your CV model, you’re going to have a better functioning model that can more accurately predict and see. Another aspect to consider of CV model dataset quality is the range of data points included in the set. For example, you want the images in your dataset to cover every real-world scenario that your CV model may encounter. If your training data isn’t diverse or suffers from a bias in a lack of data, then so will your CV model. High quality data that’s accurately annotated can go a long way towards creating a successful CV model.How Can I Avoid Bias in My Computer Vision Data Set?
Another common question people face when looking for the right dataset is how to evaluate it for bias. There are a number of different ways in which training data bias can negatively impact the accuracy of a CV model. While bias is often thought of as racism or sexism, when it comes to data the idea is more broad. Bias is anything that’s missing from your dataset. One of the most common forms of bias in a dataset is when the dataset doesn’t accurately represent the real world circumstances in which your CV model will be working. It’s important for your dataset to be as representative as possible of the real world scenarios in which your model will find itself. When creating your training dataset, it’s important to consider factors such as:- Seasonal trends
- Geographic differences
- Image angle
- Background






