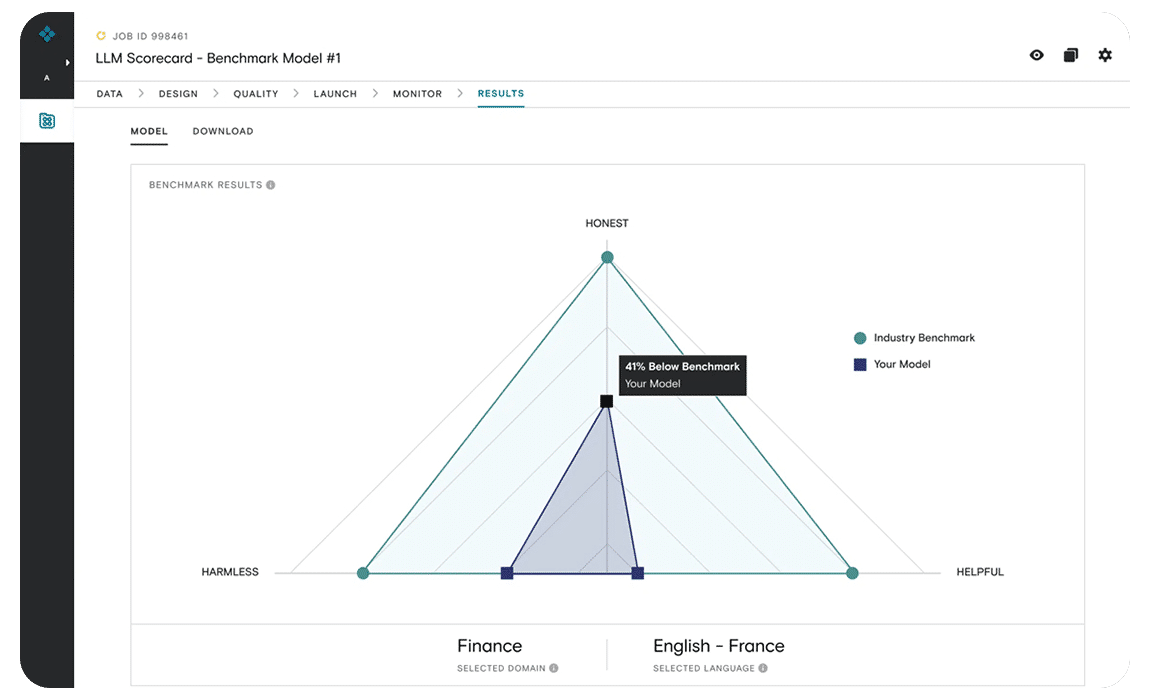
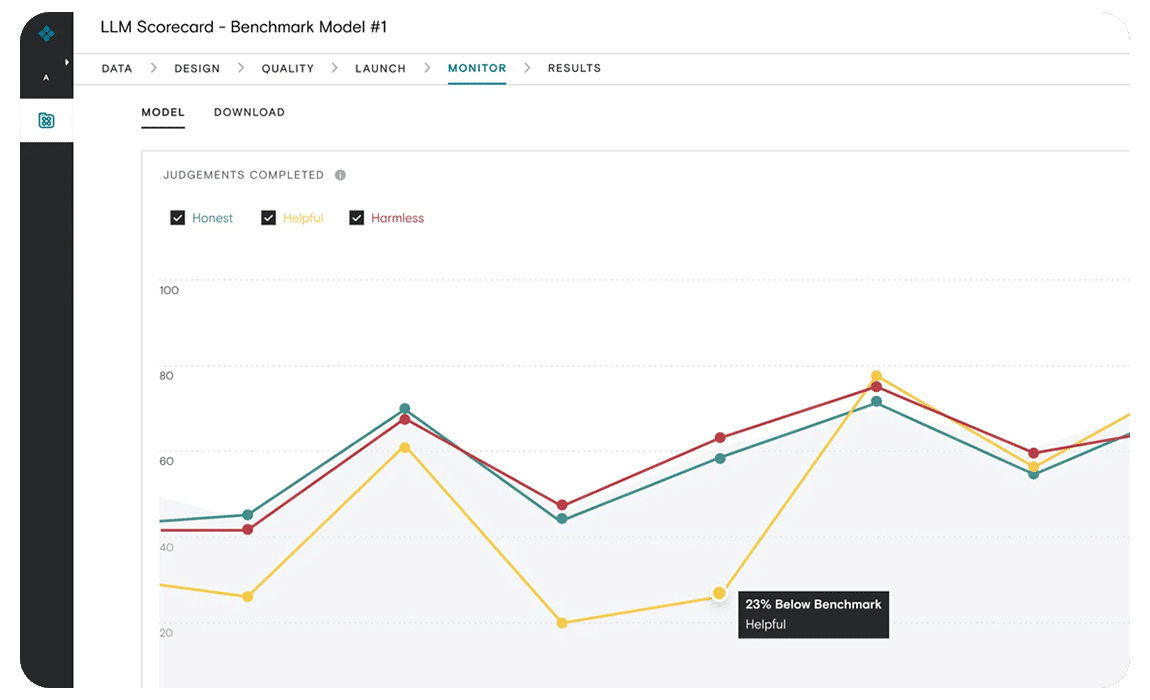
Annotation tools powered by machine learning
Annotate data faster and at scale with machine-learning assisted annotation tools that provide a comprehensive data-labeling solution. Machine learning assistance is built into our industry leading annotation tools to save customers time, effort, and money – delivering high-quality training data and accelerating the ROI on your AI initiatives.
ML-assisted frame-by-frame annotation
Frame-by-frame annotation powered by machine learning assistance that predicts the position of objects and automatically tracks them, reducing contributor fatigue.
Annotation types available: Bounding boxes, cuboids, lines, points, polygons, segmentation, ellipse, classification.
ML-assisted image annotation
Pre-trained image classification models that can help you save time and money by automating data labeling, and only sending low-confidence rows for human labeling.
Pixel masks that are automatically generated and applied to an image for contributor validation, saving time and effort.
Annotation types available: Bounding boxes, cuboids, lines, points, polygons, segmentation, ellipse, classification.
ML-assisted text annotation
Built-in tokenizers and pre-trained quality models such as duplicate detection, coherence detection, language detection, and automatic phonetic transcriptions ensuring the highest accuracy while saving time and money.
Access to Appen’s extensive language expertise, giving support for even the rarest languages such as Bodo, Khasi, Mizo etc., and ability to recruit bi-lingual participants for such rare languages in a short timeframe.
Annotation types available: Classification, Named Entity Recognition, Relationships Transcription, Transliteration, Translation, Ranking, Generation, RLHF, Comparison, Prompt-Response Pairs.
Get more value from your documents
Transform hardcopy and digital documents into a useable data source. From tables to handwriting to multi-page pdfs, use our in-tool object character recognition for faster labeling. Pre-labeling available for bounding boxes and transcriptions for typed text or handwriting.
Annotation types available: Classification, polygons, bounding boxes.
All-in-one audio tooling for clear and crisp audio annotations and transcriptions
Quick, high-quality audio transcripts with acoustic tags in a variety of languages that leverage NLP to improve transcription quality and efficiency. Audio that’s automatically segmented into different speakers, audio snippets, languages, domain and topic classification, and more for faster audio annotation.
Annotation types available: Classification, Transcription, Segment, Timestamp, Assign Speakers.
Human and ML-assisted sensor annotation
Human and machine intelligence that annotates point cloud frames (3D point cloud and RGB images) with point cloud calibration, cuboid annotation, auto-adjust, and pixel-level annotation.
3D sensor tooling that has a robust suite of features and includes machine learning assistance so you can annotate specific data quickly and accurately, building training data for your unique use cases.