Training Data
Our unique approach to providing you with reliable training data
Deploy World-Class AI Confidently With Our Reliable Training Data
To successfully deploy AI solutions, you need the right training data, and a lot of it. Partner with us to access the crowd, platform, and expertise needed to generate world-class, reliable training data at scale.
What is Training Data and Why is it Important?
Training data is labeled data used to teach AI models or machine learning algorithms to make proper decisions.
For example, if you are trying to build a model for a self-driving car, the training data will include images and videos labeled to identify cars vs street signs vs people. If you are creating a customer service chatbot, the data may be all the different ways to ask "what is my account balance?" both in text and audio, which is then translated to different languages.
Training data is paramount to the success of any AI model or project. Think of it as garbage in, garbage out. If you train a model with poor-quality data, then how can you expect it to perform? You can’t and it won’t.
You may have the most appropriate algorithm, but if you train your machine on bad data, then it will learn the wrong lessons, fail expectations, and not work as you (or your customers) expect. Your success is almost entirely reliant on your data.

Training Data 101 Webinar
Why Appen
Training data isn’t labeled or collected on its own. Human intelligence is required to create and annotate reliable training data. Our high-quality training data is possible thanks to our:

Platform
Our platform collects and labels images, text, speech, audio, video, and sensor data to help you build, train, and continuously improve the most innovative artificial intelligence systems. In addition to specialized and precise tooling, several of our tools have Smart Labeling capabilities that leverages machine learning to enhance quality, accuracy, and annotation speed.

Crowd
To produce the volume of training data required to confidently deploy world-class models, you’ll need an army of contributors and an experienced crowd management service to ensure annotators are identified and certified to your specifications. We are proud to offer a crowd of over one million contributors, in over 130 countries, and supporting over 180 different languages.

Expertise
With over 20 years of experience scoping and delivering more than 6,000 ML projects, we understand the complex needs of today's AI projects. Our solutions provide the quality, security, and speed used by leaders in technology, automotive, financial services, retail, manufacturing, and governments worldwide.
AI Training Data – Part of One Continuous Flywheel
The AI development process is like a continuous flywheel with data being the connection that makes the flywheel go round. Since it all starts with AI training data, it needs to be top-notch to proceed with an AI-based approach confidently. Whether you’re looking at what went right, what went wrong, or an explanation for what is happening with your model, a large number of problems wind up being identified with the quality, quantity, and completeness with AI training data. After all, continuing the self-driving car example from above, if a model doesn’t know the difference between a car and a street sign, how can it be expected to learn properly? The answer is that it cannot reasonably have this expectation assigned to it.
So how does it impact other parts of the AI development flywheel? When you start training your model, you’ll then want to validate that it is trained correctly. You will need test data to see how it does, and then, likely, you’ll need more training data to further tune your model for areas where the model didn’t or couldn’t make an accurate prediction. Once your model is performing the way you would like, it’s critical to refresh your model regularly to ensure that your model evolves as human behavior does.
Sit Down With Appen to Put the Right Foot Forward
The best way to make sure that your model is set up for success is to ensure the defining steps of model development are set up properly. That means getting your AI training data pipeline set up properly. By working with an organization that has a world-leading understanding of AI training data and how to put parameters in place that maximize the speed, efficiency, and quality of your system’s learning capabilities, your AI initiatives will be set up to properly reach your business goals. At Appen, we’ll take the time needed to learn about what you’re doing and what you’d like to accomplish with your model. We recognize that no two organizations follow the same path in their development needs, and we’re here to help you define yours.
Additional Training Data Resources
E-Book: The Essential Guide to Training Data for AI and ML
Blog Post: How Off-the-Shelf Training Datasets Can Save Your Machine Learning Teams Time and Money
Video: High Quality Training Data for Machine Learning
Customers Running World-Class AI


YOUR TRUSTED PARTNER FOR AI DATA
Conversational & Generative AI
Build NLP based experiences for voice assistants, translation, and customer service. Take applications to the next level by generating hyper-personalized content with Generative AI.
Computer Vision
Detect shopper's physical features and movements to overlay virtual images of products onto customers for visualization before purchasing. It can also be used to develop in-store self-check-out capabilities, inventory management and fraud detection.
Catalog
Leverage our retail domain experts with broad language understanding to execute product categorization, attribute tagging, product verification, competitive analysis, image annotation, taxonomy design, and more!
Mobile Location Data
Enable ‘to-your-door’ delivery with reduced costs through accurate underlying maps. Improve route planning for workforce efficiency and establish new warehouses with contextual attributes and photos.
Types of Training Data
Text
Deploy text-based natural language processing with data that’s collected, labeled, and validated in a wide array of languages.

Images
Add computer vision to your machine learning capabilities by collecting and understanding image classification, or leveraging pixel labeling semantic segmentation.

Audio
Build interfaces that process audio with data that is collected as utterances, time stamped, and categorized across more than 180 languages and dialects.

Video
Combine the best of audio and image annotation to process video and turn it into actionable training data for machine learning. Teach your model to understand video inputs, detect objects, and make decisions.

Sensor
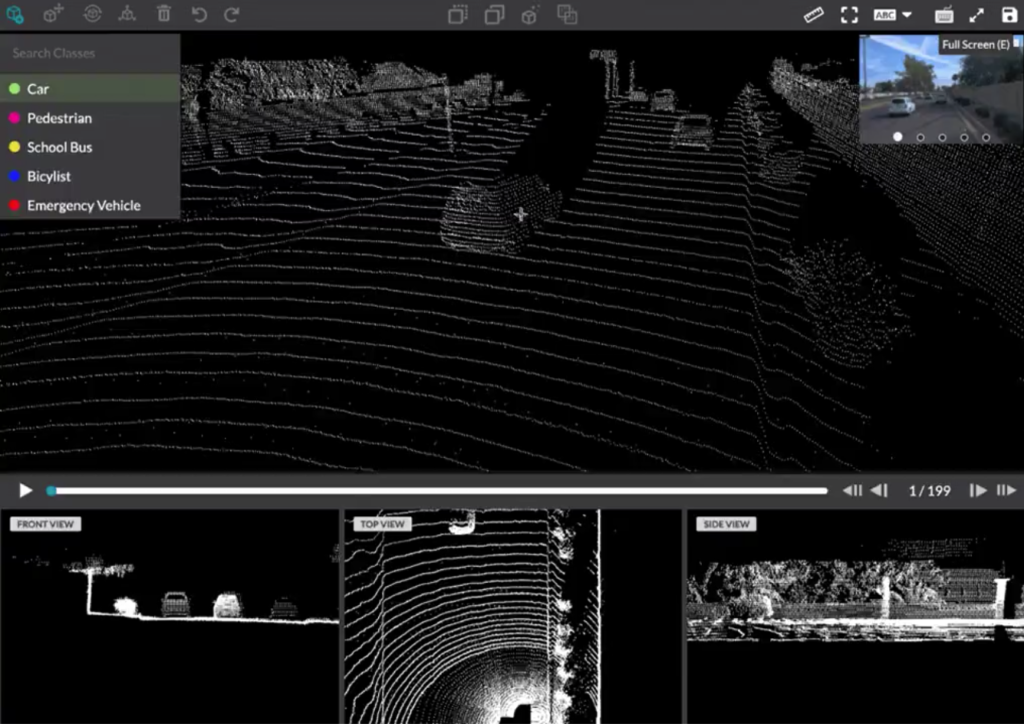
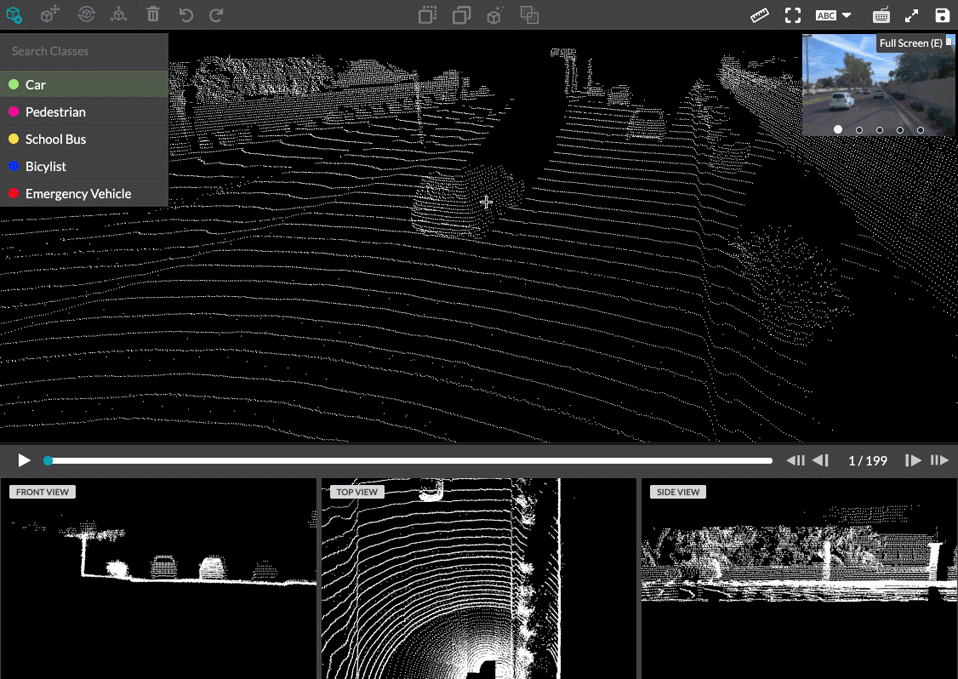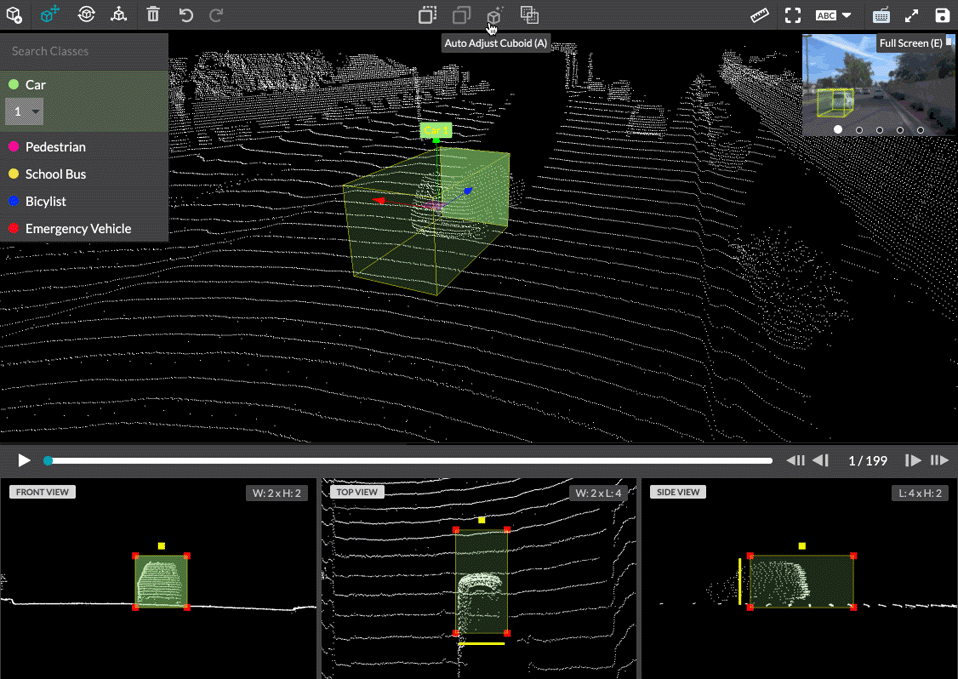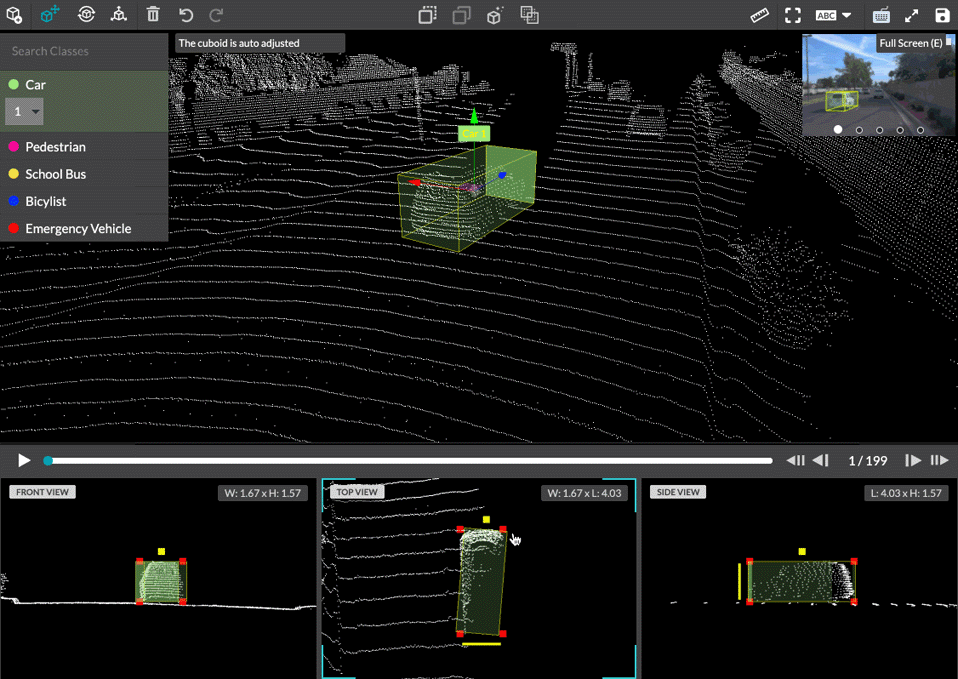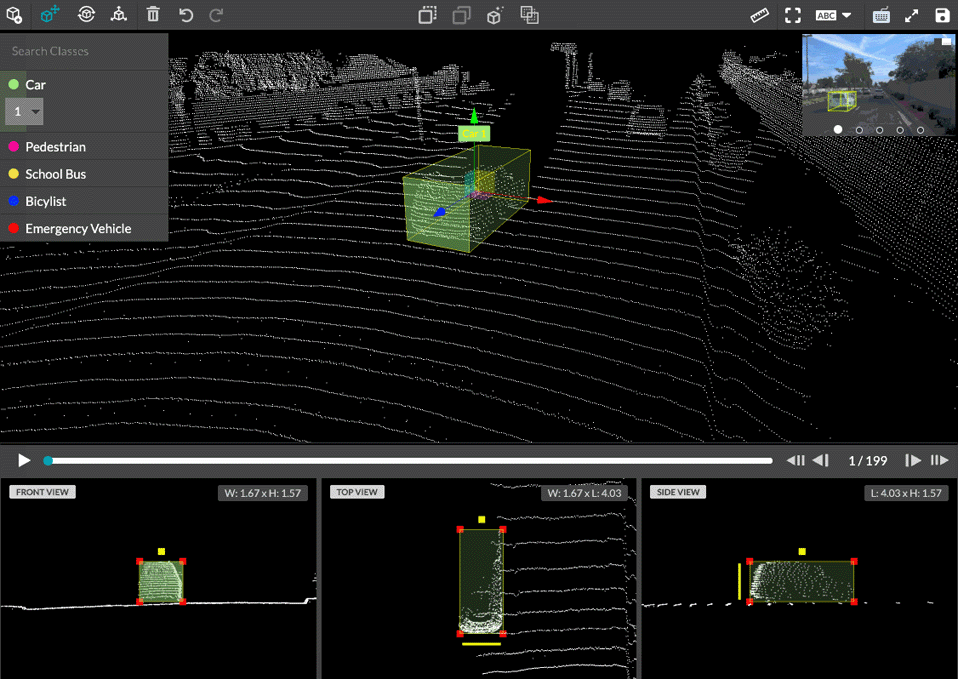
Leverage even more data points by annotating data coming directly from sensors and enable machine learning models to make decisions on a variety of data sources including LiDAR and Point Cloud Annotation.




Secure Data Access
Data security requirements are met for customers working with personally identifiable information (PII), protected health information (PHI), and other sophisticated compliance needs.
Enterprise-level security to protect sensitive client data




Secure Crowd
We offer a suite of secure service offerings with flexible options to ensure data security via secure facilities, secure remote workers, and onsite services to meet specific business needs.
Enterprise-level security to protect sensitive client data
Secure Facilities
We have sites in multiple geographies to support projects with Personally Identifiable Information (PII) and other sensitive data, as well as the right people, policies, and processes in place for a range of security levels, up to government level certification.
Enterprise-level security to protect sensitive client data
Secure Workspace
With our ISO 27001 accredited remote Secure Workspace solution, our global crowd can work on your sensitive projects remotely, without having to access a physical secure facility. This allows the diversity of our remote crowd to reduce bias and support multiple languages even through global disruptions.
Enterprise-level security to protect sensitive client data